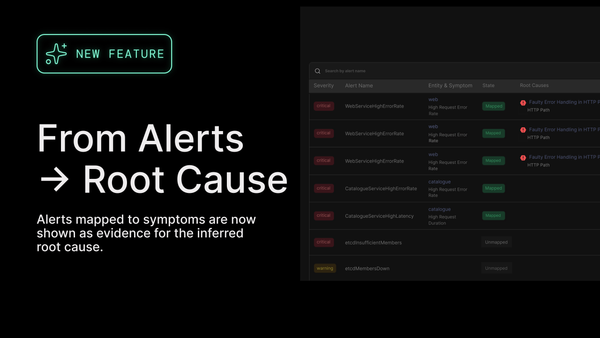
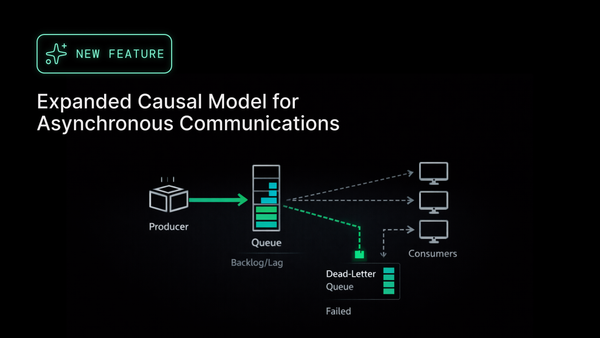
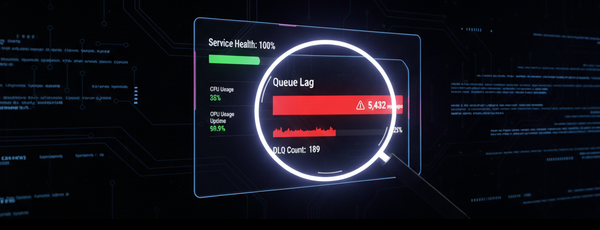
How Humm Group Delivered Flawlessly in a High-Stakes Product Launch
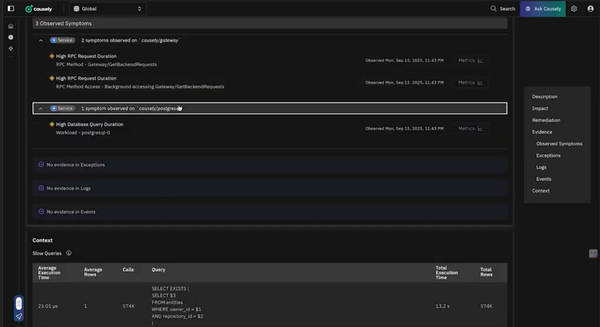
Launching a new fintech product required certainty across a complex microservices platform. With Causely modeling cause-and-effect relationships across services, Humm Group gained system-level understanding and confidence that critical dependencies behaved correctly during launch.