Alerts Aren’t the Investigation
Alerts are supposed to start an investigation. Too often, they start translation: what is the system doing right now? That translation slows containment, splinters context, and stretches customer impact.


PagerDuty fires: CheckoutAPI burn rate (2m/1h). Grafana shows p99 going from ~120ms to ~900ms. Retries doubled. DB CPU is flat, but checkout pods are throttling and a downstream dependency’s error budget is evaporating. Ten minutes in, you’ve collected artifacts, not understanding.
If you’ve been on call, you’ve seen this movie.
This is also why plenty of “AI-powered observability” rollouts still don’t change the lived experience of on-call. Leadership expects response times to improve. On-call gets richer dashboards, smarter summaries, and more plausible explanations. To be fair, those do help with faster lookup and briefing in the room, but the social reality stays the same: alerts get silenced in PagerDuty, rules get tagged as “flappy,” and old pages keep firing long after anyone can justify what they were meant to protect. The problem isn’t effort. It’s that the page still doesn’t reliably collapse into shared understanding. Call it the Page-to-Understanding Gap: the time and coordination cost of turning a threshold into a system story.
Alerts are supposed to start an investigation. Too often, they start translation: what is the system doing right now? That translation slows containment, splinters context, and stretches customer impact.
That decoding work is what incident response depends on, yet it’s rarely made explicit. It’s why MTTR gains often plateau even after teams invest heavily in monitoring and dashboards.
Alerts are a paging interface, not a language of explanation
Alerting is optimized for one job: interrupt a human at the right moment.
So alerts are built from what’s easiest to express at scale: thresholds, proxy signals, and rules that “usually work.” They encode operational history, not system truth.
That’s not a failure of alerting. It’s what alerting is for, but it also makes alerts a shaky foundation for understanding. They’re a simplified label over messy reality. When alerts aren’t grounded in clear definitions of “healthy” behavior, the signal loses meaning and teams stop trusting it.
One alert name can mean multiple different realities
Take a familiar page: “latency high,” or the modern equivalent: an SLO burn rate page.
Burn rate fires on checkout. You assume checkout is slow, start in the service dashboard, see p99 up, then notice retries doubled. Meanwhile, Slack is already split: “DB” vs. “checkout.” Fifteen minutes later you realize a downstream dependency is brownouting and checkout is just drowning in retries. The giveaway is usually the shape: one hop shows rising timeouts and retry storms while upstream looks "healthy" until it saturates. The alert didn’t lie—it just didn’t tell you what you needed first.
The page looks identical. The mechanism isn’t.
So teams build muscle memory around “what usually causes this,” and it works—until the system changes just enough that it stops working. Scale and change are exactly what modern organizations optimize for, so the failure mode is guaranteed. When that happens, the alert doesn’t just wake you up. It points you in the wrong direction.
Many alerts can describe the same underlying behavior
The reverse problem happens just as often. A single degradation creates a cascade of pages across services: latency, errors, saturation, queueing, burn rate alarms. Each is technically “true,” but treating them as separate problems creates thrash.
People split into parallel investigations, duplicate context gathering, and argue about which page is “the real one.” Context fragments across Slack threads and war rooms, ownership ping‑pongs, and escalations get noisy. By the time you agree which page is “primary,” you’ve already created a coordination incident. The outcome isn’t just wasted engineer time—it’s that nobody has one shared narrative everyone can repeat while impact is unfolding. The incident becomes less about understanding and more about sorting competing signals. This is how alert fatigue turns into incident fatigue.
The silent gap: important behavior you don’t alert on
The costly ones are the slow degradations that ship impact before they page.
A dependency gets a little slower. Retries creep up. One critical route starts timing out for a slice of customers. Averages look fine. Thresholds don’t trip. You don’t notice until the page fires, or until customers do.
It’s not that teams don’t care. It’s that these behaviors don’t fit neatly into alert rules: risk builds up, dependencies decay, partial impact hides in aggregates, and propagation only makes sense once you’ve traced it end to end.
Most alerts only get defined after you’ve understood the behavior in the middle of an incident. The post-mortem produces a new rule and a brief feeling of closure. Then traffic shifts, dependencies evolve, and the next incident arrives with a different shape. You’re never done.
So teams find these late, after impact is already underway, when time is most expensive.
Why teams don’t switch investigation entry points
When teams adopt a new investigation system, they often ask a simple question: “Does it match our alerts?”
What they’re really asking is: “Can I trust this in the first 90 seconds?” Because in the first minute, the primary goal isn’t elegance, it’s not making it worse.
A system that generates more hypotheses doesn’t help if it can’t connect the page to what the system is doing in a way the on-call trusts.
If the system describes an incident in a different language than the alert model engineers rely on, mismatches get interpreted as duplication, contradiction, or risk. The result is predictable: people consult it late, after they’ve already committed to a direction.
Even correct insights arrive too late to change behavior.
Why this problem is getting worse
Systems are becoming more dynamic: more dependencies, faster deploys, and more integration points. Deploy frequency keeps climbing—and AI-assisted coding is only accelerating it—so the number of failure paths keeps growing. Meanwhile, alert fatigue is already high, and teams are hesitant to change workflows mid-incident.
Better tooling can speed up lookup and correlation, but it can’t compensate for an alerting model that no longer maps cleanly to real system behavior.
So the interpretation workload keeps rising. Every page demands more interpretation, more cross-checking, more manual stitching of symptoms into a coherent story.
What’s actually broken
Most organizations are operating with two different languages: the language of paging and the language of understanding. The persistent MTTR plateau is the Page-to-Understanding Gap between them.
Incidents start with the first, but the work happens in the second.
A better way to think about alerts
Alerts are not the investigation. They’re a notification that something is going sideways.
The goal is not to tune thresholds until the noise feels tolerable. It’s to shorten the time from page to shared understanding: what behavior is emerging, what changed, what’s being impacted—and whether it matters to the business.
Treating that translation as unwritten know‑how is not a workflow quirk. It’s a structural weakness. If your incident response starts with decoding alerts, you’re spending your best engineers on interpretation instead of containment.
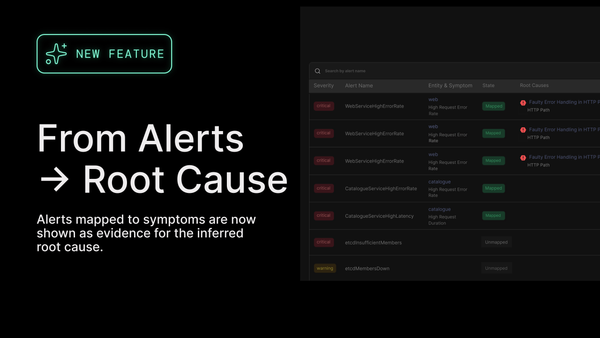
Shipped in v1.0.114: Now each ingested alert is mapped to the symptom it represents and shown directly in the context of the inferred root cause. Alerts are no longer just timestamps and labels. They become part of a coherent system story.