In 2025, I resolve to be smarter about observability data
Collecting “more data” has been the defining characteristic of observability practices and tools for the last few decades. But over-collection creates inefficiencies, noise, and cost without adding meaningful value. This trajectory must and can be changed.

Observability isn’t about how much data you collect—it’s about how much insight you can gain to keep your systems running.
Collecting “more data” has been the defining characteristic of observability practices and tools for the last few decades. The allure of multiple tools that instrument virtually every layer of the stack, from applications to infrastructure and beyond, traps us into believing that more data equals more insights. But the reality is often the opposite: over-collection creates inefficiencies, noise, and cost without adding meaningful value. As I said during a recent podcast interview, it may make you less blind, but not necessarily smarter.
Instead of clarifying what’s happening in your systems, excessive data leads to confusion. Teams are inundated with redundant metrics, irrelevant logs, and false-positive alerts. Each new piece of data requires engineers to interpret, process, and correlate, pulling focus away from actionable insights. As a result, observability becomes a “big data” problem, where the volume of information collected outweighs its usefulness.
We always collected too much data, but microservices architectures and the new emerging instrumentation, eBPF and OpenTelemetry, exacerbate the problem. With tens of thousands of microservices, each collecting even a few metrics every few seconds, adds up very quickly to millions of data points requiring overloaded processing and terabytes of storage. The realization that we need application instrumentation to get insights about the higher layer on the stack and the interactions between services led to the adoption of eBPF and OpenTelemetry, but with these came a tsunami of traces that overwhelms observability tools and makes them practically useless.
This trajectory must and can be changed.
When collecting data offers diminishing returns
Collecting data turns observability into a “big data problem” instead of its intended purpose: to keep systems up and running. As a result, you don’t simply apply a band-aid to a bullet hole, you end up applying band-aids upon band-aids upon band-aids. Each new big data problem results in more big data solutions, which result in more big data problems, and the cycle continues.
Lack of purpose creates noise
Observability data is often collected without a clear sense of purpose. Teams instrument everything they can, thinking it might be useful someday, but this creates a flood of irrelevant information. The result is alert fatigue, where low-priority or false-positive alerts drown out the critical signals engineers need to act on. In Kubernetes environments, for example, native instrumentation combined with third-party tools often generates more metrics than teams can effectively use, adding complexity instead of clarity.
Earlier this week, we wrote about the difficulties of troubleshooting problems in production. Excessive data only makes the haystack larger; it doesn’t help you find the needle any faster.
Ask yourself: what percentage of the collected and stored data is ever being looked at? What is the cost of processing and storing this data?

Fragmentation of observability tools
Observability is highly fragmented, with different tools collecting and processing data in silos. Each technology or layer of the application stack is monitored by a point tool that monitors that specific technology or layer. The applications may be monitored by an APM tool like Datadog, New Relic, or Dynatrace. The services layer may be monitored by eBPF and OpenTelemetry. The Kubernetes infrastructure may be monitored by the native Kubernetes instrumentation. Cloud services may be monitored by cloud provider’s tools like CloudWatch. And the list goes on.
Some of these tools collect metrics, some collect traces, and others ingest logs or events. Regardless of whether these point tools come from different vendors or are provided by a single vendor, each one of them has its own data model. They lack not only a unified data model, but a common semantic model to interpret the data to analyze the data across the entire stack and to provide actionable insights. Engineers are left to manually correlate information across dashboards, increasing time to resolution. This fragmentation creates inefficiencies that undermine the very purpose of observability: delivering actionable insights.
Ask yourself:
How many different point tools are you using?
Which one do you use when and why?
How much of the data is redundant?
Overhead of storing and processing data
Storing and analyzing vast amounts of observability data comes at a cost—both financial and operational. Many tools charge by data volume, making it cost-prohibitive to retain all collected data. Even for teams with generous budgets, processing and querying such large datasets consumes time and resources, often delivering diminishing returns.
Ask yourself:
Are you in the business of collecting observability data or are you in the business of keeping your systems running reliably and efficiently?
A top-down approach to observability
The solution isn’t more data—it’s the right data. A top-down approach flips the traditional model of observability on its head. Instead of starting with what data is available, start with the purpose: what are you trying to achieve?
Define the goals first—whether it’s root cause analysis, SLO compliance, or performance optimization—and then work down to identify the data needed to support those goals.
Building the right analytics is critical. Analytics should be purpose-built to deliver insights that directly address the goals you’ve defined. For example, if the goal is to identify bottlenecks, focus on analytics that analyzes service latencies, instead of drowning in utilization metrics.
Finally, only collect the data you need. With the purpose and analytics in place, you can focus on gathering metrics and logs that directly contribute to actionable insights. This reduces noise, eliminates unnecessary alerts, and lowers the overhead of storing and processing data.
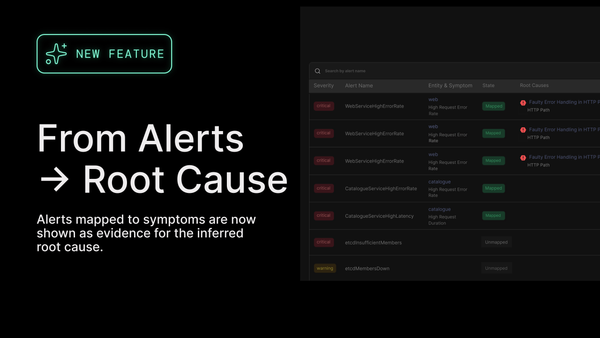
Causely helps you focus on what matters
Our Causal Reasoning Platform is a model-driven, purpose-built AI system delivering multiple analytics built on a common data model. It is designed to minimize data collection while maximizing insight. (You can learn more about how it works here).
As a result, Causely is laser focused on collecting only the metrics, traces, and logs required as input for the above analytics. This dramatically reduces the amount of data collected by Causely. Furthermore, all the raw metrics and traces are processed locally in real time, and none if it is pushed out to the cloud. The only information pushed to the back-end analytics in the cloud is the topology and symptoms. The only data stored in the cloud are the pinpointed root causes and the contextual information associated with the root causes. This minimizes Causely's TCO!
Conclusion
Collecting more data doesn’t guarantee better observability. In fact, it often creates more problems than it solves. A top-down approach—starting with purpose, building targeted analytics, and focusing on necessary data—streamlines observability and makes it actionable. Platforms like Causely enable this approach, helping teams move beyond the big data trap and focus on delivering real value. Observability isn’t about how much data you collect—it’s about how much insight you can gain.
This week, we covered numerous ways teams can shift their posture from reactive infrastructure fixes to more proactive observability. Organizations that are more proactive will enjoy several benefits, including:
- Spending less time troubleshooting
- Preventing escalations from devolving into finger-pointing and blame
- Predicting the impact of changes before they are deployed
- Planning for future environment and infrastructure changes
Book a meeting with the Causely team and let us show you how you can bridge the gap between development and observability to build better, more reliable cloud-native applications.