Causely: Continuous service reliability root cause hunting
Originally posted to Intellyx by Jason English.


Originally posted to Intellyx by Jason English.
An Intellyx Brain Candy Brief
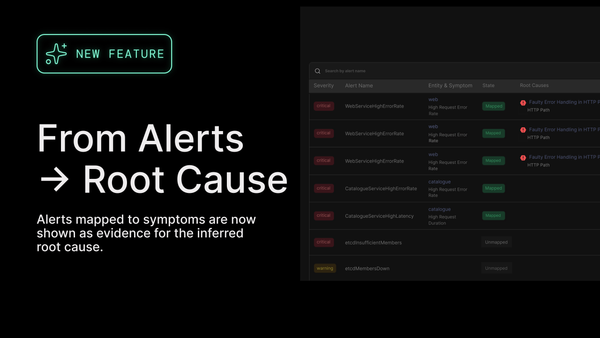
Causely monitors a real-time Bayesian network of semantically abstracted runtime operational telemetry data in order to observe and alert engineers to highly probable causes of issues and failure conditions, so they can ideally be resolved before they can emerge as customer-facing incidents.
Their “Causal Inference System” is a directed acyclic graph populated with tons of possible failure mode indicators. You can think of these indicators like micro-CVEs for observability, so that the system can know what to look for as it passively observes payloads within OTel logs and traces alongside golden signals such as latency or errors. It’s not another AI SRE, as the inferences it surfaces are deterministically based on live indicators that are semantically enriched with context.
When causes are observed, they can be captured as feedback so DevOps teams can flow through changes in the next CI/CD cycle, or reported into the enterprise’s incident management, ITSM and observability tools of choice, with direct links to contextual insights.
Sure, you could still do root cause hunting with any major observability platform worth its salt. However, to do that for a large distributed enterprise system, you would need to define thousands of policies that collect and tag telemetry data, and set up triggers and automation for each, such that the cognitive load and cloud data costs to keep it current might be prohibitively high. There’s always another way to do things!