How Causal AI Is Transforming SRE Reliability in Kubernetes Environments
Originally posted to TFIR by Monika Chauhan. Causely’s Severin Neumann explains how causal reasoning, MCP, and AI-driven automation are transforming SRE workflows and Kubernetes reliability.


Originally posted to TFIR by Monika Chauhan.
SRE teams are hitting a breaking point as Kubernetes environments scale faster than traditional workflows can keep up. Alerts pile up, incidents drag on, and teams lose hours in reactive firefighting instead of building reliability into their systems. At KubeCon + CloudNativeCon in Atlanta, Severin Neumann, Head of Community at Causely, offered a clear perspective on how AI can finally shift SRE practice from reactive to proactive. But this requires more than feeding logs into an LLM — it requires causal reasoning.
For years, the industry has talked about proactive SRE, but the reality rarely matches the aspiration. Neumann has spent more than a decade in observability and monitoring, and in his experience, teams always circle back to the same pattern: there’s an alert, teams react, things stabilize, and then the cycle starts again. The promise of AI offered a potential breakthrough, but early attempts fell into a familiar trap.
When companies say “AI SRE,” many immediately think of a large language model interpreting alerts and suggesting fixes. Neumann stressed that this approach often works only at the surface level. LLMs are powerful in pattern matching and summarization, but they don’t understand systems the way SREs need them to. They can connect correlations, but they can’t determine causation. And in high-pressure incident situations, an AI hallucination is more than an annoyance — it can waste hours and cost companies real money.
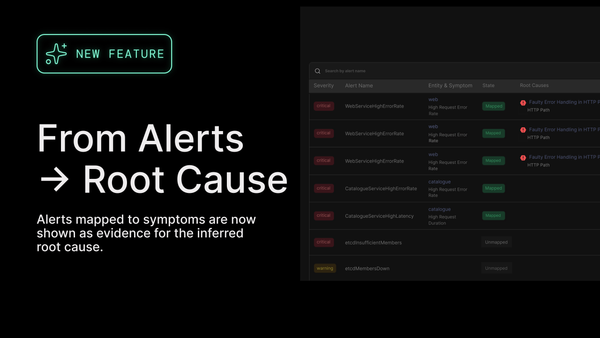
Causely takes a different approach. Their platform is built on a causal model that understands the structural relationships inside Kubernetes environments. Instead of giving an LLM raw observability data and hoping it finds meaning, Causely creates a deterministic model of how services interact and what components influence one another. The model knows which symptoms map to which possible root causes and can identify the single cause that explains them all.
This is a critical shift. Instead of chasing noisy correlations, SRE teams can rely on a reasoning engine that explains exactly why a problem is happening. LLMs do come into the picture, but only after the causal model has already identified the issue. At that point, a language model can help generate explanations, provide remediation guidance, or suggest kubectl or Helm commands to fix the problem. The heavy lifting — the understanding — remains deterministic.
Neumann also explained why this approach stands apart in the industry. Many teams tried the LLM-first path and burned their fingers. Some built internal solutions, others adopted competitors, but most eventually discovered the limitations. LLMs often fail when precision matters most, and in distributed systems, precision is everything. One misleading answer can waste hours in the middle of a firefight.
Causely’s causal reasoning avoids that by grounding all decisions in a model built around real system behavior. This also sets the stage for a more ambitious goal: shifting reliability left. Instead of waiting for symptoms, the model can analyze normal system behavior and identify bottlenecks or weak points before they cause downtime. This turns SRE work from reaction into prevention.
The conversation also explored the role of MCP (Model Context Protocol). Causely launched their MCP Server at KubeCon, enabling developers to pull causal insights directly into tools they already use. Through MCP, the remediation guidance — including detailed commands — can appear directly in an IDE or command line. The SRE no longer has to dig through logs or dashboards to figure out what’s going wrong. The causal model does that work and surfaces the fix.
Neumann outlined a vision where, over time, teams can set boundaries that allow AI to autonomously remediate certain classes of issues. If a service needs to scale up or memory needs to be increased, those actions could eventually be automated within limits defined by humans. This is where AI becomes a genuine partner — one that teams can trust to handle repetitive corrective tasks while they focus on system design, SLOs, and reliability architecture.
Trust is a key theme. Introducing AI into SRE workflows doesn’t eliminate human responsibility; it shifts it. Humans now become orchestrators who decide when to delegate and when to intervene. As Neumann put it, the more trust teams build in the system, the more they can remove themselves from situations where they’re no longer needed. This opens space for deeper reliability engineering, building guardrails, and designing better services.
A real-world example makes the value of causal reasoning clear. Imagine a financial services company running hundreds of microservices. Suddenly, everything turns red and user transactions fail. Traditional debugging would mean looking across alerts, logs, and traces to guess where the bottleneck is. Causely can cut straight through the noise, identify the one overloaded service, and surface the exact command needed to scale it up or adjust its memory. The time shaved off matters — for reliability, user experience, and cost.
Throughout the conversation, it became evident that AI isn’t replacing SREs. It’s allowing them to finally escape the cycle of constant firefighting. With causal reasoning, proactive reliability, and tools like MCP, SREs can shift to roles that emphasize guidance, architecture, and strategic improvements rather than crisis management.