How We Used Causely to Solve a Crashing Bug in Our Own App—Fast

At Causely, we don’t just ship software – we run a reasoning platform designed to detect, diagnose, and resolve failure conditions with minimal human intervention. Our own cloud-native application runs in a highly distributed environment, with dozens of interdependent microservices communicating in real-time. It’s complex, dynamic, and constantly evolving—just like the environments our customers run.
Recently, we encountered an issue that perfectly illustrates the value of Causely’s Causal Reasoning Platform in action.
A Crash That Didn’t Want to Be Found
While reviewing our staging environment— which uses our existing OpenTelemetry instrumentation to identify root causes in our production deployment of Causely — I noticed something disturbing: a frequent crash failure had been quietly recurring over six days in one of our analytics microservices.
This type of issue is notoriously difficult to detect. The logs were noisy. The failures were intermittent. The symptoms appeared scattered—some in one analysis module, others in a different component entirely. This issue would’ve gone unnoticed in most environments or been chalked up to transient behavior. But Causely identified the cause. Not as an alert or a spike in a dashboard – but as an active root cause that is impacting our system. It wasn’t just showing us individual failures. It was showing us causality - the propagation behind the symptoms.
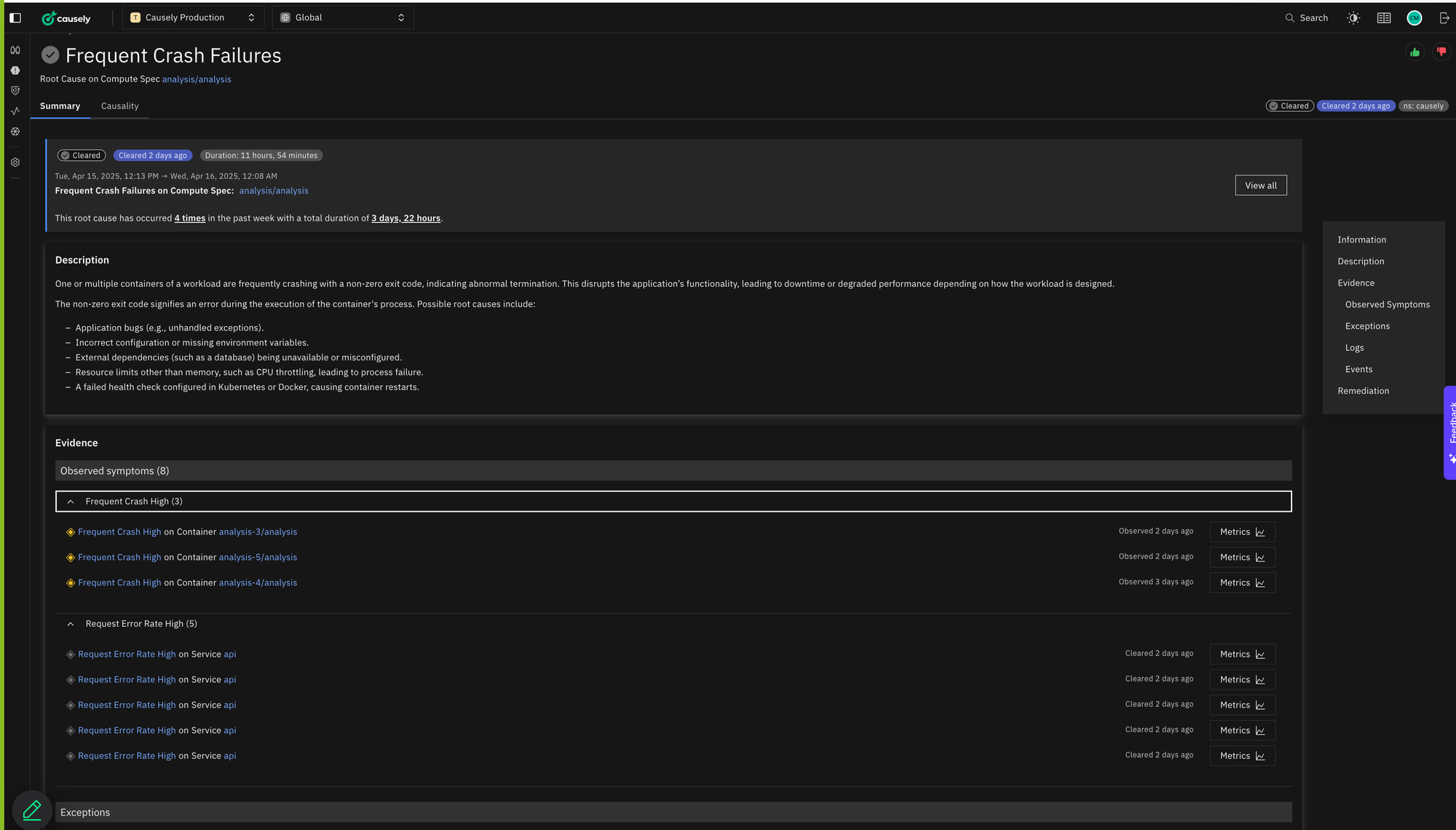
Different subcomponents—analysis-3, analysis-5—were failing in seemingly unrelated ways. One had high error rates; another had frequent panics. Without Causely, we would’ve been chasing these symptoms in isolation. Logging into pods, checking dashboards, comparing timelines. A manual, time-consuming wild goose chase.
What Causely Did Differently
Causely automatically inferred these separate symptoms across services and time into a single root cause: a concurrency issue in a shared in-memory map used across multiple analysis workers.
The issue? A concurrent write-read condition that would only manifest under higher-volume conditions – something nearly impossible to catch in development or test environments. But Causely connected the dots through symptom propagation and causal relationships, allowing us to zero in on the problem fast.
Technical Deep Dive: The Bug Behind the Crash
The crash was caused by concurrent access to a Go map, which is unsafe for concurrent reads and writes without explicit synchronization.
We were using a plain map [string]SomeStruct to store intermediate analysis results across worker goroutines. This map was being:
- Written to by one thread collecting event evidence in real time
- Read from simultaneously by another thread responsible for emitting outputs
Under low volume, this worked fine. But under sustained load in production, the race condition emerged—resulting in panics like:
fatal error: concurrent map read and map write
This is a classic Go gotcha. The fix was straightforward: we wrapped the map with a sync.RWMutex to protect both reads and writes, ensuring thread safety. Alternatively, we could have used a sync.Map, but since our access patterns were relatively simple and performance-sensitive, the mutex approach was more appropriate.
This was one of those bugs where:
- It was impossible to reproduce locally
- The crash symptoms varied depending on which thread accessed the map first
- And the logs, while technically correct, gave no useful hint unless you already suspected the concurrency issue
Without Causely surfacing the underlying causality across services and across time, this would have remained an intermittent ghost bug.
From Root Cause to Resolution – In Hours, Not Days
Thanks to the inference Causely provided, we identified the concurrency bug, coded a fix, and shipped it – all within a couple of hours.
This wasn’t just about speed. It was about precision. Without Causely, our team might have:
- Spent days troubleshooting unrelated alerts and errors
- Overlooked the root cause due to insufficient signal
- Delayed resolving an issue that was actively degrading reliability
Why This Matters
Crashes like these don’t always surface in ways traditional monitoring or modern observability systems can catch. They emerge over time, appear intermittent, and produce symptoms that span components.
Causely gave us what observability tools couldn’t: contextual understanding. Observability tools show you context. Causely helps you understand it. It didn’t just tell us something was broken. It told us what was breaking, why, and what needed to change.
This is the power of causal reasoning over correlation.
We built Causely to operate in the most demanding environments – and we hold ourselves to that same standard. This incident was a clear example of how our platform enables us to move faster, with more confidence, and resolve issues before they impact users.
And that’s exactly the kind of reliability we aim to bring to every engineering team.