The Signal in the Storm: Why Chasing More Data Misses the Point
More telemetry doesn’t guarantee more understanding. In many cases, it gives you the illusion of control while silently eroding your ability to reason about the system.


As OpenTelemetry adoption has exploded, so has the volume of telemetry data moving through modern observability pipelines. But despite collecting more logs, metrics, and traces than ever before, teams are still struggling to answer the most basic questions during incidents: What broke? Where? And why?
In my recent talk at OpenTelemetry Community Day, “The Signal in the Storm: Practical Strategies for Managing Telemetry Overload,” I laid out a different path forward, one focused not on volume, but on meaning.
More telemetry doesn’t guarantee more understanding. In many cases, it gives you the illusion of control while silently eroding your ability to reason about the system. That illusion becomes expensive, especially when telemetry pipelines are optimized for ingestion, not insight.
Observability Needs a Better Model
Traditional observability relies on emitting and aggregating raw signals (spans, logs, and metrics), then querying across that pile post-hoc. That model assumes the data will be useful after something goes wrong. But today’s distributed, dynamic, multi-tenant AI-driven systems don’t give you that luxury. The cost of collecting all raw signals without semantics and without context is too high.
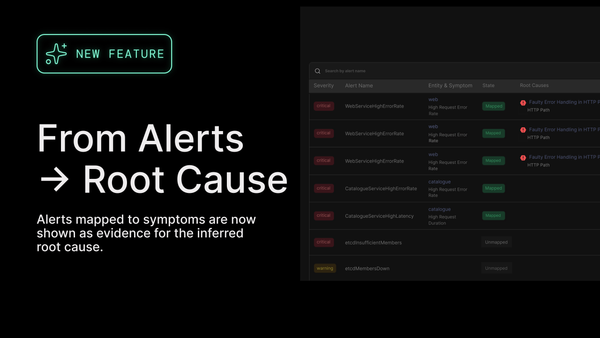
We need a shift: from streams of telemetry to structured, semantic representations of how systems behave. That starts by modeling the actual components of the system (entities) and the relationships between them. Not as metadata bolted onto spans, but as first-class signals. This is the work being advanced by the OpenTelemetry Entities SIG, and it's central to how we think about observability at Causely.
What It Looks Like in Practice
At Causely, we’ve been applying these ideas in production. We observe system behavior, and instead of centralizing all that raw output, we extract anomalies in the context of semantic entities and relationship graphs at the edge. This gives us fine-grained insight without overwhelming the pipeline.
The impact is real:
- Less data, more clarity: structured signals replace noisy aggregates
- Better performance and cost-efficiency: telemetry becomes lean and targeted
- Stronger privacy: raw, user-level data never needs to leave the cluster
- Faster debugging: understanding is built-in, not reverse-engineered
The goal isn’t to eliminate data; it’s to collect with intent. To make the system itself understandable, not just observable.
Watch the Talk
In the session, I go deep into what this looks like technically, including:
- How teams are adapting their telemetry strategies to manage scale and cost
- The role of entities, ontologies, and semantic modeling in modern observability
- Why centralized data lakes aren’t a sustainable long-term answer
- What we’ve learned building systems that can reason about their own behavior
If you’ve felt the limits of traditional observability, and you're looking for a more scalable, reliable, and thoughtful path forward, I hope you’ll check it out.
See the slides, or watch the recording: