Causely Expands Datadog Integration to Deliver Causal Intelligence Across Hybrid Environments
Causely’s expanded Datadog integration turns Datadog APM signals into system-level causal intelligence, helping teams understand how issues propagate across services and pinpoint true root cause.


Causely is expanding its Datadog integration to address a problem every senior engineering team eventually runs into: observability data keeps growing, but confidence during incidents does not. Even with Datadog APM, infrastructure metrics, and monitors deployed everywhere, engineers are still forced to interpret symptoms and argue about which change or dependency actually caused an outage. The issue is not missing telemetry. It is the lack of a system-level understanding of cause and effect.
This limitation becomes especially visible in modern, hybrid architectures. Services span Kubernetes clusters, standalone EC2 instances, ECS tasks, and legacy infrastructure, all connected through real production traffic. Datadog can surface signals across these environments, but understanding how failures propagate across those boundaries remains a manual, error-prone exercise. The result is slower recovery, repeated incidents, and reduced confidence in change.
With this expanded Datadog integration, Causely gives teams a unified, causal model of their entire application across Kubernetes and non-Kubernetes environments. This model that explains why services are impacted, not just where symptoms appear.
From Observability Signals to System Understanding
Many teams already rely on Datadog APM, infrastructure metrics, and monitors as the backbone of their observability stack. With Causely’s expanded support, those same Datadog signals can now be used to build a complete and accurate causal model of the system without changing existing instrumentation.
Causely supports Datadog APM dual shipping, which allows trace data to be sent directly from the Datadog collector into Causely’s mediator. Teams continue using Datadog exactly as they do today, while Causely consumes the same traces for causal reasoning. This approach avoids additional agents, avoids data duplication, and does not introduce new egress costs.
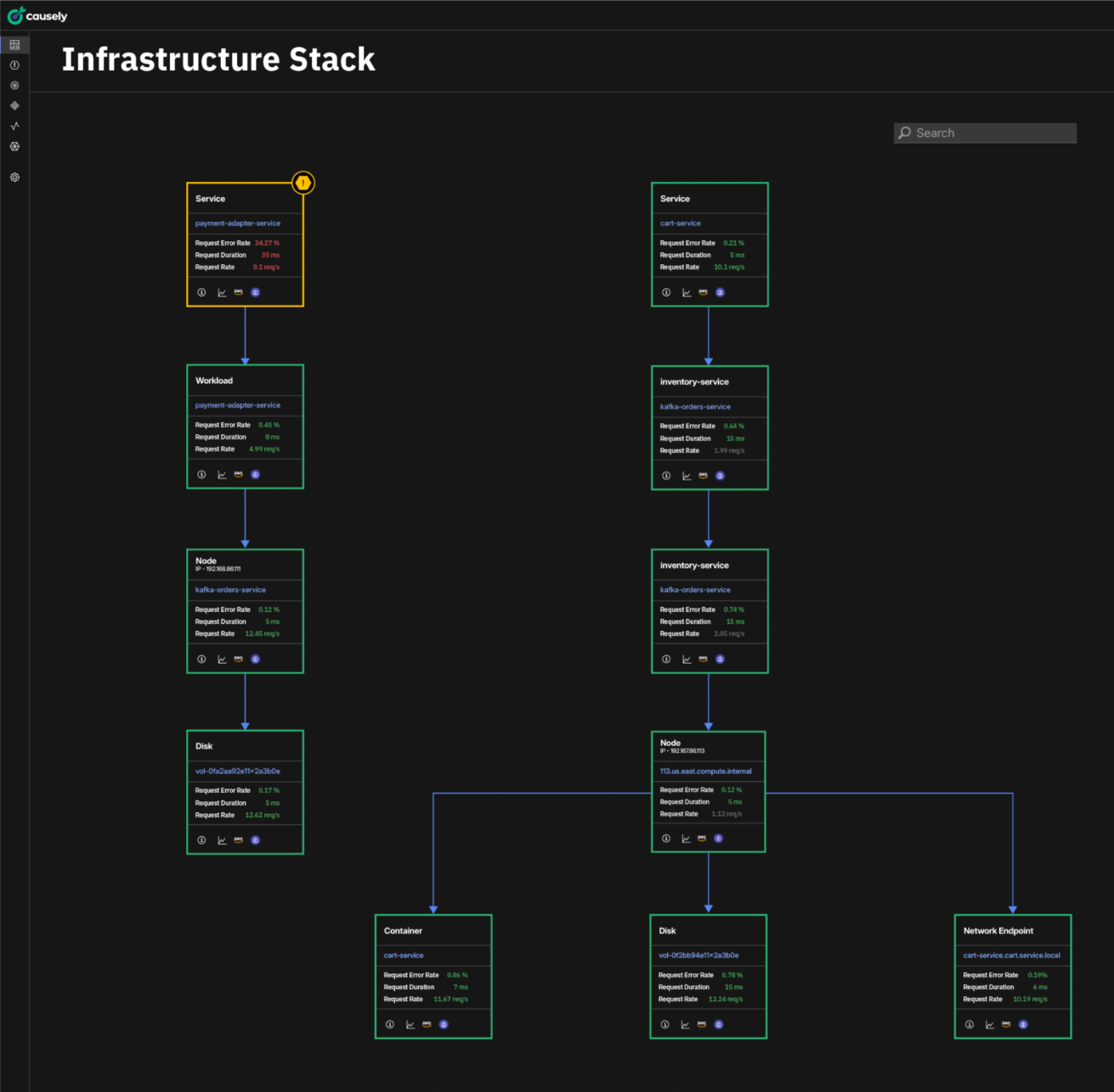
Just as importantly, Causely now supports services running outside Kubernetes and keeps causality intact across the hybrid boundary. By tagging Datadog APM traces with host identity metadata, Causely can stitch together services running on EC2 with those running inside Kubernetes clusters. What previously broke at environment boundaries becomes a single, end-to-end behavioral model of how the application actually runs in production.
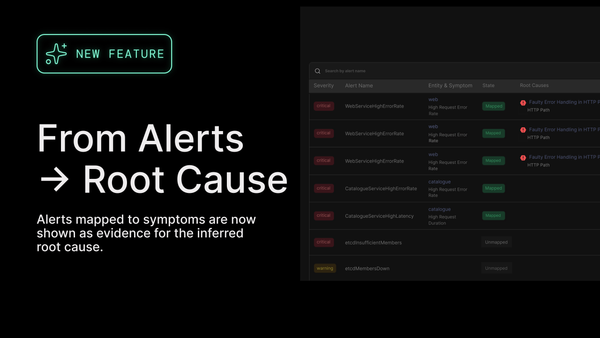
Datadog monitors can also be ingested directly into Causely and treated as symptoms rather than conclusions. Instead of reacting to alerts in isolation, Causely uses them as signals that inform its understanding of what is happening in the system and why. That’s how you get faster convergence, fewer false leads, and higher confidence in the fix.
A Real-World Hybrid Application Scenario
Consider a typical production application. Customer-facing APIs and frontend services run in a Kubernetes cluster. Background workers, billing services, or legacy processing jobs run on standalone EC2 instances. The application depends on shared infrastructure such as Postgres, Redis, and external APIs. Datadog is already deployed across all of it.
Under normal conditions, everything appears healthy. Then, during a traffic spike, latency starts creeping up in one of the Kubernetes services. Shortly after, Datadog monitors begin firing for elevated error rates in downstream components. Engineers open dashboards, inspect traces, and try to correlate timelines across environments. The symptoms are visible, but the cause is not obvious.
This is where Causely changes the workflow.
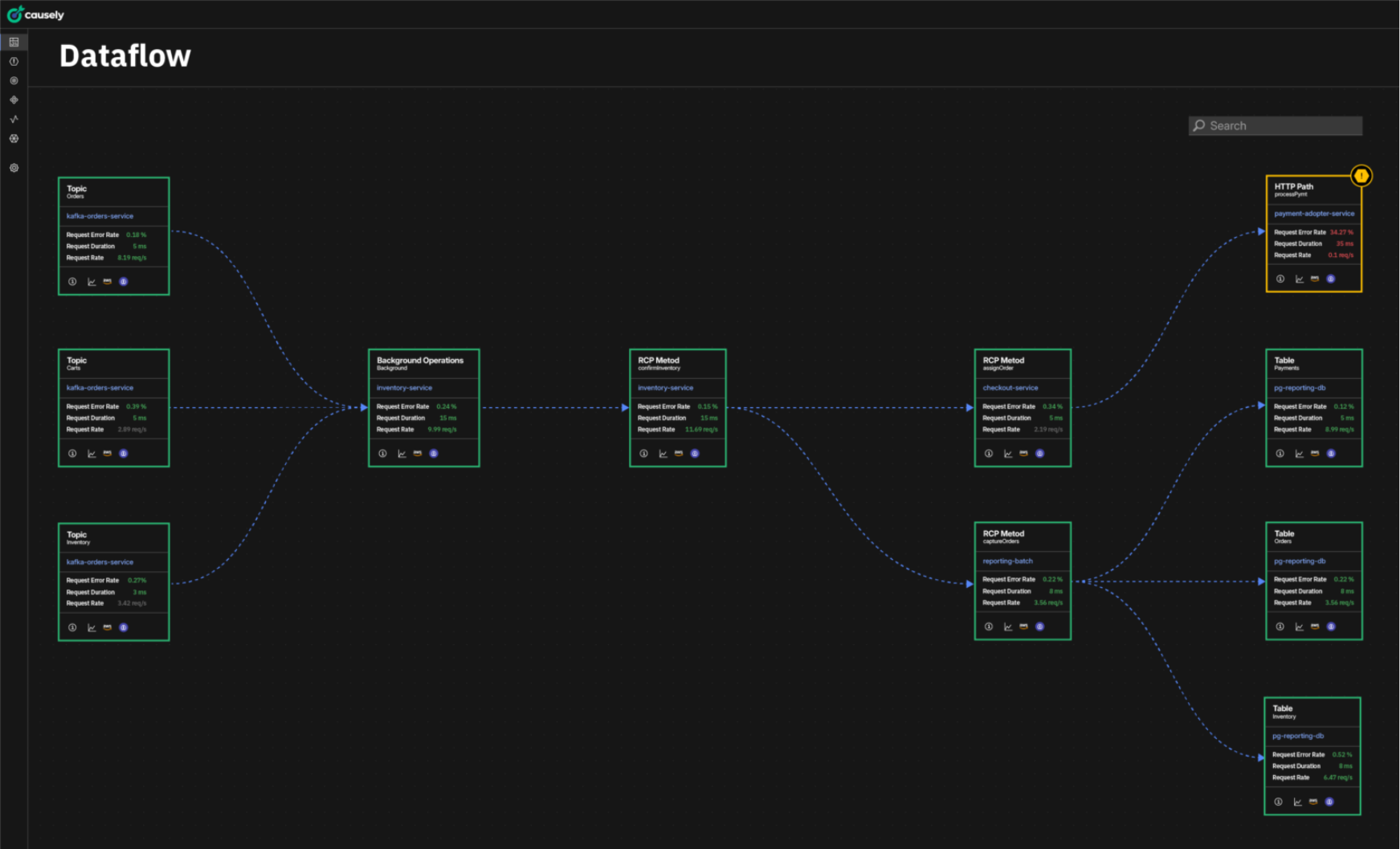
Automatically Pinpointing the True Cause
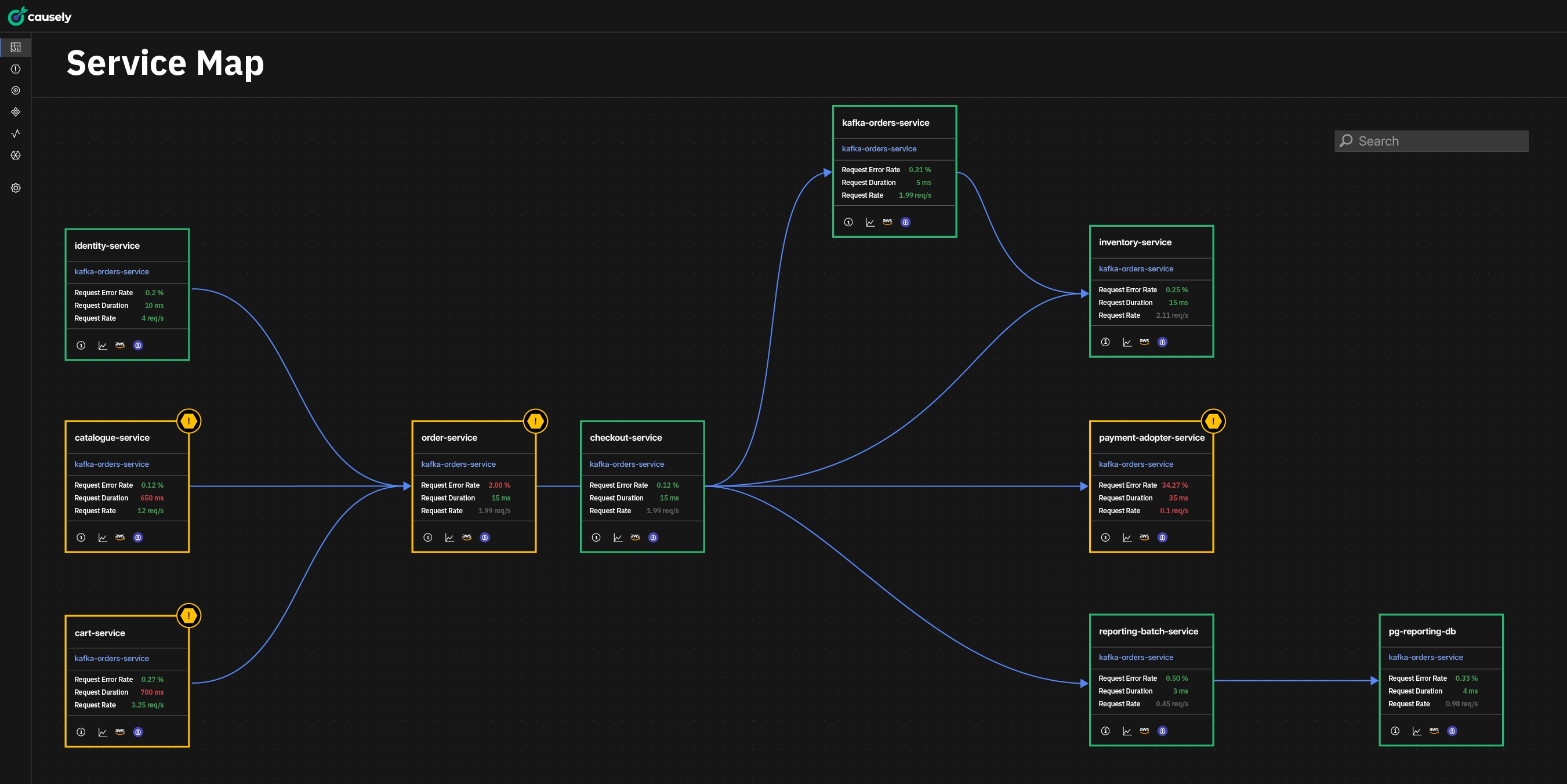
Using Datadog traces, infrastructure metadata, and monitor events, Causely continuously reconstructs end-to-end request paths and dependencies across Kubernetes and EC2. That continuity holds across environment boundaries, so you don’t have to manually stitch together “what talks to what” in the middle of an incident. Instead of reacting to individual alerts, Causely continuously builds and maintains a behavioral model of the entire system. This model captures how services, infrastructure, and data flows interact, and how specific failure modes produce observable symptoms.
Datadog APM traces provide the raw evidence of system behavior, including service interactions, request paths, and downstream dependencies. Datadog monitors are ingested and mapped as symptoms within Causely’s knowledge base. Together, these signals allow Causely to maintain an up-to-date causal model that explicitly links observed symptoms to the conditions and changes that produced them.
Because this causal model is updated continuously, Causely can explain not just what is failing, but what changed first, how the impact propagated, and why specific services or endpoints are affected. The result is a precise, system-level explanation of performance degradation that teams can act on immediately.
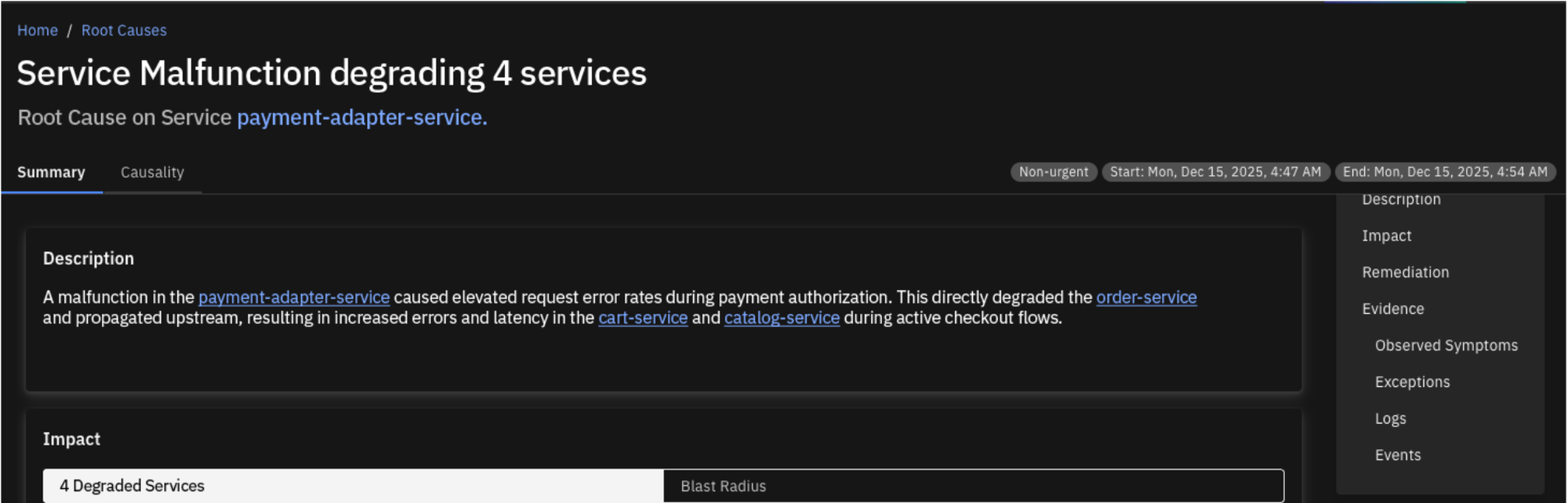
From Incident Response to Reliability Assurance
This expanded Datadog integration is not just about faster root cause analysis during incidents. By continuously modeling system behavior, Causely enables teams to validate reliability before changes reach production, monitor how reliability evolves over time, and detect drift caused by infrastructure or configuration changes.
Modern systems are hybrid by default, and reliability problems do not respect environment boundaries. To operate confidently at scale, teams need more than visibility. They need to understand how their systems behave and why failures occur.
With expanded Datadog support across Kubernetes and EC2, Causely helps teams move from alert-driven firefighting to causal reliability engineering. The result is fewer war rooms, faster resolution, and the confidence to ship changes without fear.
To learn more about using Causely with Datadog, explore the integration guide or reach out to see a unified service graph in action.