How a Leading Gaming Platform Prevented Revenue Loss Using Causely in Grafana
With Causely + Grafana, the gaming platform can spot reliability risks early, take the right action, and avoid revenue-impacting incidents before users even notice.


In live sports betting, every second counts. That’s why a major interactive gaming company brought Causely’s AI SRE into Grafana. With Causely, they can now spot reliability risks early, take the right action, and avoid revenue-impacting incidents before users even notice.
The Stakes: Real-Time Bets, Real-Time Risk
For this industry-leading platform, performance is crucial. During live events, hundreds of thousands of users rely on the app to place bets in real time. If a service slows down, bets fail. If latency spikes, revenue is lost. There’s no buffer for outages, and no time for guesswork.
Many of the platform’s highest-traffic moments, such as marquee games, playoff weekends, or last-minute betting surges, occur on weekends or late at night. This adds strain on a small team that's already stretched thin, often pulling engineers into incident response during off hours, when the toll on focus, sleep, and morale is highest.
The company had modern observability tools in place, including Grafana dashboards, Prometheus metrics, and alerting pipelines. But when something went wrong, their SREs still had to hunt for the cause across a vast array of charts and logs. They needed something that could connect the dots for them, quickly and accurately.
The Challenge: Observability Without Clarity
Like many teams operating large-scale microservices architectures, they have invested in and standardized on an observability platform that provides lots of visibility. What the team lacked was understanding to enable rapid decision-making. They could see when something was breaking, but not why, or what to fix first.
The complexity came not just from the number of services, but from the nature of the system itself. Services communicated asynchronously over messaging queues, wrote to distributed databases, and scaled dynamically based on real-time load. These components operated independently yet were deeply interdependent with one another. During peak sporting events, traffic could spike dramatically in seconds. This created unpredictable cascades of latency, retries, and congestion.
Under these conditions, their observability tools struggled to identify the real cause of issues. Dashboards showed metric anomalies. Alerts fired across disconnected tools. However, understanding what was actually happening required engineers to mentally reconstruct a constantly shifting topology and then guess at the most likely root cause based on limited data.
Each incident became a manual, high-stakes investigation. Teams would dig through logs and traces, cross-reference alerts, and escalate issues across multiple teams to determine where to start. That meant long triage loops, missed SLOs, and far too much time reacting instead of preventing.
What they needed was a system that could keep up with the complexity, something that could analyze the real-time behavior of the entire environment, understand how changes ripple across services, and surface what matters before user impact.
The Solution: Causal Reasoning Embedded in Grafana
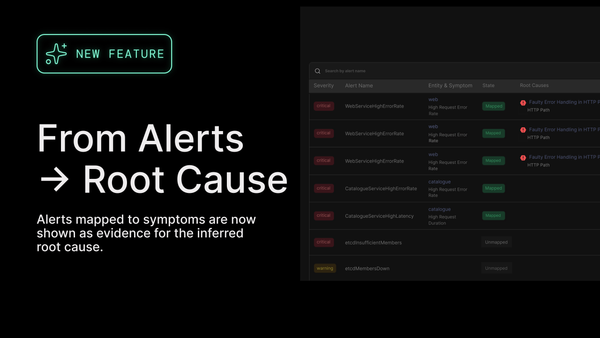
To close this gap, the team rolled out Causely’s Grafana plugin. It gave their SREs a new layer of intelligence, right inside the dashboards they already use.
Causely continuously consumes telemetry from their existing observability tools and applies causal reasoning to identify what matters. It answers three essential questions:
Where is the problem?
What is it?
And why did it happen?
With that context, Causely enables remediation, either by guiding engineers to the right action or automating it through AI.
In this case, when service latency began trending in the wrong direction, Causely didn’t just trigger an alert. It identified the actual cause, explained the potential blast radius, and gave the team the confidence to act quickly, without second-guessing or escalating the situation.
The Outcome: Reliability Under Constant Change
During a major live event, the platform began showing early signs of degradation. But instead of spinning up a war room, the SRE team used Causely to trace the issue to a misconfigured connection pool in an upstream service, before end users were ever impacted.
They resolved the issue fast, stayed within SLOs, and avoided revenue loss during one of their busiest betting windows. There was no guesswork, no back-and-forth, and no missed opportunities.
See It at ObservabilityCon
Causely will be at Grafana’s ObservabilityCon, showing how causal reasoning is helping engineering teams stay ahead of incidents—and focus on building, not firefighting.
Want a 1:1 walkthrough before the event?
Causely turns observability into action.
It brings clarity, speed, and confidence to every incident—right from your existing Grafana workflows.